Learning TensorFlow #1 - Using Computer Vision to turn a Chessboard image into chess tiles
I've been wanting to learn how to use TensorFlow, an open-source library that google recently released for machine learning and other applications. The introductory tutorials are great, teaching how to classify written numbers, but it would be nice to try something different and new.
So what sort of problems could we solve? Well, one problem that I'd been having involved chess. There's a web forum called Reddit, which has several subforums (they call them subreddits) where people can post about specific topics, in this case the one I'm interested in is the chess subreddit. About once or twice a day someone will publish a new post that links to an image of a 2D online chessboard in a certain layout.
They're either from games, or sometimes are called tactics puzzles, which is where a person is given a certain layout of chess pieces and tries to guess the next best move or series of moves for one of the sides. A lot of the times, after guessing the sequence, I wanted to check the layout and my move choices on an online chess analysis engine, such as Lichess, but having to put all the pieces together on an editor online was annoying on a computer, and obnoxious on a cellphone.
So the question is, can we build and train a system that can take these images in and find the layout, as well as automatically generate a link to an analysis engine?
1st attempt at Input Data
So what sort of problems could we solve? Well, one problem that I'd been having involved chess. There's a web forum called Reddit, which has several subforums (they call them subreddits) where people can post about specific topics, in this case the one I'm interested in is the chess subreddit. About once or twice a day someone will publish a new post that links to an image of a 2D online chessboard in a certain layout.
 |
| An example chess puzzle image posted on /r/chess |
So the question is, can we build and train a system that can take these images in and find the layout, as well as automatically generate a link to an analysis engine?
Figuring out the Input and Outputs
To figure out the answer, we need to look at the expected inputs and outputs for our system, let's start with what we know we want:1st attempt at Input Data
- Posted images come from several sources, the majority are lichess.org and chess.com website screenshots, but there are several from cellphone apps, the facebook app, and other random websites.
- Several of the posted images are not well-cropped, in fact some are screenshots from a cell phone where the chessboard is only a small part of the image.
- On lichess alone there are 280 different combinations of piece graphics and chessboard background themes, this number gets bigger when we include other chess sites.
- Images can have annotations and highlighting of pieces
- Images are orthorectified (lines of chessboard horizontal/vertical), 2D and have clean graphics, perfect.
1st attempt at Output Data
- A predicted Forsyth-Edwards Notation (FEN) , a standard notation for a chessboard layout. It's a set of characters describing each of the 64 tiles on a chessboard. This can be used to generate a link to the online analysis engines.
If we look at this as is, it's plausible, but if we wanted to get full coverage of the input space, we would need several thousands of chessboard images for each reasonable different theme and piece set to get reasonable coverage of the space. We'd essentially have to provide enough training data for a neural network to be able to find a chessboard in an image, know to look at each tile, and then finally predict the tiles. It would need a lot of data to not overfit to certain configuration of pieces, or themes, and the backgrounds of the screenshots outside of the chessboard.
We don't really need to train an ML algorithm to find chessboard and tiles, we can actually take advantage of the fact that input images are pretty uniformly orthorectified and do some basic computer vision to find and slice up chessboard images into 64 input tiles. We can define an input image as a single chess tile, resized and converted to a 32x32 grayscale image. So each input image is 1024 float values 0-1 range. Now lets look at our inputs and outputs again:
2nd attempt at Input Data
- 32x32 grayscale normalized image of a single chess tile containing a piece or empty
2nd attempt at Output Data
- A label for which piece we think it is, there are 6 white pieces and 6 black pieces, and 1 more for an empty square, so 13 possible choices.
Perfect! The input data is extremely simple and uniform, and the output data is a single choice from 13 possible options, or a 13 length one-hot label vector in machine learning speak. This is ideal, and extremely similar in setup to the starter tensorflow tutorial.
Now all we need to do is turn a poorly cropped online chessboard image into 64 chess tiles,
Note: Check out the IPython notebook where I actually do what I'm describing here.
As a summary, the technique was to do a Hough transform of the image space to find the lines in the image. However, we can further simplify the space because we know the only lines we care about are horizontal and vertical lines, shrinking our Hough space into just two vectors essentially. We can find the horizontal and vertical gradients, then sum them along the axes to look for the strongest lines in those axes. Doing this gets us several lines, including the edges of chessboard and random lines from screenshots of webpages. We can actually take advantage of another property of most chessboard images, which is that the tiles alternate in color, resulting in a gradient that consistently flips along the axis, like in this image:
So instead of just looking for the strongest gradients in an axis, we can look for the strongest positive and negative gradients along an axis, the amplitude in this case, a unique property that the internal 7 chessboard lines will have most of the time (some images have solid black lines along the internal chessboard lines, we'll cross that bridge another day).
 |
| Gradient of an image in X, black is negative, white is positive. |
 |
| (top) Gradient in X. (bottom) Amplitude of gradients in X & Y |
Then, we do some statistical kung-fu to find a set of 7 lines with consistent spacing, this was a bit obnoxious but I'll spare you the details. Finally we now have our pixel-perfect detection of a chessboard!
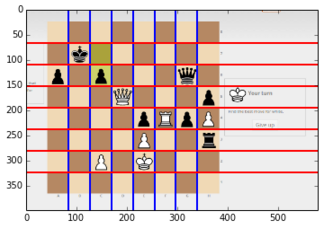 |
| Chessboard lines found in a screenshot |
Using this, we can trivially slice up the image into tiles, resize and grayscale them using the python imaging library into 32x32 pieces, and form a large matrix of 64x32x32 tiles for one chessboard. We save each tile as it's own image, here's one example tile:
Now we know how to generate input data, in the next post, I'll discuss how we generate a couple thousand such tiles with an associated label for training a machine learning algorithm.
 |
| A black pawn 32x32 grayscale tile |


